Dpdk
Author 晓兵
weixin: ssbandjl
公众号: 云原生云
![]()
Data Plane Development Kit (DPDK)
Data Plane Development Kit (DPDK) greatly boosts packet processing performance and throughput, allowing more time for data plane applications.
DPDK can improve packet processing performance by up to ten times. DPDK software running on current generation Intel® Xeon® Processor E5-2658 v4, achieves 233 Gbps (347 Mpps) of L3 forwarding at 64-byte packet sizes.1 As a result, telecom and network equipment manufacturers (TEMs and NEMs) can lower development costs, use fewer tools and support teams, and get to market faster.
数据平面开发套件 (DPDK) 极大地提升了数据包处理性能和吞吐量,为数据平面应用留出更多时间。
DPDK 最多可将数据包处理性能提高十倍。 在当前一代英特尔® 至强® 处理器 E5-2658 v4 上运行的 DPDK 软件在 64 字节数据包大小下实现了 233 Gbps (347 Mpps) 的 L3 转发。因此,电信和网络设备制造商(TEM 和 NEM)可以降低 开发成本,使用更少的工具和支持团队,更快地进入市场。
Developers can use DPDK to consolidate workloads into a single architecture, for a more scalable and simplified solution.
开发人员可以使用 DPDK 将工作负载整合到单一架构中,以获得更具扩展性和简化的解决方案。
DPDK程序启动后只能有一个主线程,然后创建一些子线程并绑定到指定CPU核心上运行
In a world where the network is becoming fundamental to the way people communicate, performance, throughput, and latency are increasingly important for applications like wireless core and access, wireline infrastructure, routers, load balancers, firewalls, video streaming, VoIP, and more. By enabling very fast packet processing, DPDK is making it possible for the telecommunications industry to move performance-sensitive applications like the backbone for mobile networks and voice to the cloud. It was also identified as a key enabling technology for Network Functions Virtualization (NFV) in the original ETSI NFV White Paper.
在网络成为人们通信方式的基础的世界中,性能、吞吐量和延迟对于无线核心和接入、有线基础设施、路由器、负载平衡器、防火墙、视频流、VoIP 等应用程序越来越重要。 通过实现非常快速的数据包处理,DPDK 使电信行业能够将性能敏感的应用程序(如移动网络和语音的主干)转移到云端。 在最初的 ETSI NFV 白皮书中,它也被确定为网络功能虚拟化 (NFV) 的关键支持技术。
DPDK was created in 2010 by Intel and made available under a permissive open source license. The open source community was established at DPDK.org in 2013 by 6WIND and has facilitated the continued expansion of the project. Since then, the community has been continuously growing in terms of the number of contributors, patches, and contributing organizations, with 5 major releases completed including contributions from over 160 individuals from 25 different organizations. DPDK now supports all major CPU architectures and NICs from multiple vendors, which makes it ideally suited to applications that need to be portable across multiple platforms.
DPDK 由英特尔于 2010 年创建,并在宽松的开源许可下提供。 6WIND 于 2013 年在 DPDK.org 建立了开源社区,并促进了该项目的持续扩展。 从那时起,社区在贡献者、补丁和贡献组织的数量方面一直在不断增长,完成了 5 个主要版本,其中包括来自 25 个不同组织的 160 多名个人的贡献。 DPDK 现在支持来自多个供应商的所有主要 CPU 架构和 NIC,这使得它非常适合需要跨多个平台移植的应用程序。
核心组件是一组库,可提供高性能数据包处理应用程序所需的所有元素。
DPDK核心思想:
PMD:DPDK针对Intel网卡实现了基于轮询方式的PMD(Poll Mode Drivers)驱动,该驱动由API、用户空间运行的驱动程序构成,该驱动使用无中断方式直接操作网卡的接收和发送队列(除了链路状态通知仍必须采用中断方式以外)。目前PMD驱动支持Intel的大部分1G、10G和40G的网卡。PMD驱动从网卡上接收到数据包后,会直接通过DMA方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。如果要是让Linux来处理收包过程,首先网卡通过中断方式通知协议栈对数据包进行处理,协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否本机的socket,满足条件则会将数据包拷贝一份向上递交给用户socket来处理,不仅处理路径冗长,还需要从内核到应用层的一次拷贝过程。hugetlbfs: 这样有两个好处:第一是使用hugepage的内存所需的页表项比较少,对于需要大量内存的进程来说节省了很多开销,像oracle之类的大型数据库优化都使用了大页面配置;第二是TLB冲突概率降低,TLB是cpu中单独的一块高速cache,采用hugepage可以大大降低TLB miss的开销。DPDK目前支持了2M和1G两种方式的hugepage。通过修改默认/etc/grub.conf中hugepage配置为“default\_hugepagesz=1G hugepagesz=1G hugepages=32 isolcpus=0-22”,然后通过mount –t hugetlbfs nodev /mnt/huge就将hugepage文件系统hugetlbfs挂在/mnt/huge目录下,然后用户进程就可以使用mmap映射hugepage目标文件来使用大页面了。测试表明应用使用大页表比使用4K的页表性能提高10%\~15%。CPU亲缘性:多核则是每个CPU核一个线程,核心之间访问数据无需上锁。为了最大限度减少线程调度的资源消耗,需要将Linux绑定在特定的核上,释放其余核心来专供应用程序使用。同时还需要考虑CPU特性和系统是否支持NUMA架构,如果支持的话,不同插槽上CPU的进程要避免访问远端内存,尽量访问本端内存。- 减少内存访问:少用数组和指针,多用局部变量;少用全局变量;一次多访问一些数据;自己管理内存分配;进程间传递指针而非整个数据块
Cache有效性得益于空间局部性(附近的数据也会被用到)和时间局部性(今后一段时间内会被多次访问)原理,通过合理的使用cache,能够使得应用程序性能得到大幅提升- 避免
False Sharing: 多核CPU中每个核都拥有自己的L1/L2 cache,当运行多线程程序时,尽管算法上不需要共享变量,但实际执行中两个线程访问同一cache line的数据时就会引起冲突,每个线程在读取自己的数据时也会把别人的cache line读进来,这时一个核修改改变量,CPU的cache一致性算法会迫使另一个核的cache中包含该变量所在的cache line无效,这就产生了false sharing(伪共享)问题.Falsing sharing会导致大量的cache冲突,应该尽量避免。访问全局变量和动态分配内存是false sharing问题产生的根源,当然访问在内存中相邻的但完全不同的全局变量也可能会导致false sharing,多使用线程本地变量是解决false sharing的根源办法。 - 内存对齐:根据不同存储硬件的配置来优化程序,性能也能够得到极大的提升。在硬件层次,确保对象位于不同
channel和rank的起始地址,这样能保证对象并并行加载。 - 字节对齐:众所周知,内存最小的存储单元为字节,在32位CPU中,寄存器也是32位的,为了保证访问更加高效,在32位系统中变量存储的起始地址默认是4的倍数(64位系统则是8的倍数),定义一个32位变量时,只需要一次内存访问即可将变量加载到寄存器中,这些工作都是编译器完成的,不需人工干预,当然我们可以使用
\_\_attribute\_\_((aligned(n)))来改变对齐的默认值。 cache对齐,这也是程序开发中需要关注的。Cache line是CPU从内存加载数据的最小单位,一般L1 cache的cache line大小为64字节。如果CPU访问的变量不在cache中,就需要先从内存调入到cache,调度的最小单位就是cache line。因此,内存访问如果没有按照cache line边界对齐,就会多读写一次内存和cache了。NUMA:NUMA系统节点一般是由一组CPU和本地内存组成。NUMA调度器负责将进程在同一节点的CPU间调度,除非负载太高,才迁移到其它节点,但这会导致数据访问延时增大。- 减少进程上下文切换: 需要了解哪些场景会触发
CS操作。首先就介绍的就是不可控的场景:进程时间片到期;更高优先级进程抢占CPU。其次是可控场景:休眠当前进程(pthread\_cond\_wait);唤醒其它进程(pthread\_cond\_signal);加锁函数、互斥量、信号量、select、sleep等非常多函数都是可控的。对于可控场景是在应用编程需要考虑的问题,只要程序逻辑设计合理就能较少CS的次数。对于不可控场景,首先想到的是适当减少活跃进程或线程数量,因此保证活跃进程数目不超过CPU个数是一个明智的选择;然后有些场景下,我们并不知道有多少个活跃线程的时候怎么来保证上下文切换次数最少呢?这是我们就需要使用线程池模型:让每个线程工作前都持有带计数器的信号量,在信号量达到最大值之前,每个线程被唤醒时仅进行一次上下文切换,当信号量达到最大值时,其它线程都不会再竞争资源了。 - 分组预测机制,如果预测的一个分支指令加入流水线,之后却发现它是错误的分支,处理器要回退该错误预测执行的工作,再用正确的指令填充流水线。这样一个错误的预测会严重浪费时钟周期,导致程序性能下降。《计算机体系结构:量化研究方法》指出分支指令产生的性能影响为
10%\~30%,流水线越长,性能影响越大。Core i7和Xen等较新的处理器当分支预测失效时无需刷新全部流水,当错误指令加载和计算仍会导致一部分开销。分支预测中最核心的是分支目标缓冲区(Branch Target Buffer,简称BTB),每条分支指令执行后,都会BTB都会记录指令的地址及它的跳转信息。BTB一般比较小,并且采用Hash表的方式存入,在CPU取值时,直接将PC指针和BTB中记录对比来查找,如果找到了,就直接使用预测的跳转地址,如果没有记录,必须通过cache或内存取下一条指令。 - 利用流水线并发: 像
Pentium处理器就有U/V两条流水,并且可以独自独立读写缓存,循环2可以将两条指令安排在不同流水线上执行,性能得到极大提升。另外两条流水线是非对称的,简单指令(mpv,add,push,inc,cmp,lea等)可以在两条流水上并行执行、位操作和跳转操作并发的前提是在特定流水线上工作、而某些复杂指令却只能独占CPU。 - 为了利用空间局部性,同时也为了覆盖数据从内存传输到
CPU的延迟,可以在数据被用到之前就将其调入缓存,这一技术称为预取Prefetch,加载整个cache即是一种预取。CPU在进行计算过程中可以并行的对数据进行预取操作,因此预取使得数据/指令加载与CPU执行指令可以并行进行。
在最底部的内核态(Linux Kernel)DPDK 有两个模块:KNI 与 IGB\_UIO。 其中,KNI提供给用户一个使用 Linux 内核态的协议栈,以及传统的 Linux网络工具(如ethtool, ifconfig)。IGB\_UIO(igb\_uio.ko 和 kni.ko.IGB\_UIO)则借助了 UIO 技术,在初始化过程中将网卡硬件寄存器映射到用户态。
DPDK 的上层用户态由很多库组成,主要包括核心部件库(Core Libraries)、平台相关模块(Platform)、网卡轮询模式驱动模块(PMD-Natives&Virtual)、QoS库、报文转发分类算法(Classify)等几大类,用户应用程序可以使用这些库进行二次开发
The framework creates a set of libraries for specific environments through the creation of an Environment Abstraction Layer (EAL), which may be specific to a mode of the Intel® architecture (32-bit or 64-bit), Linux* user space compilers or a specific platform. These environments are created through the use of meson files and configuration files. Once the EAL library is created, the user may link with the library to create their own applications. Other libraries, outside of EAL, including the Hash, Longest Prefix Match (LPM) and rings libraries are also provided. Sample applications are provided to help show the user how to use various features of the DPDK.
该框架通过创建环境抽象层 (EAL) 为特定环境创建一组库,这些库可能特定于英特尔® 架构(32 位或 64 位)、Linux* 用户空间编译器或 一个特定的平台。 这些环境是通过使用介子文件和配置文件创建的。 创建 EAL 库后,用户可以链接到该库以创建自己的应用程序。 还提供了 EAL 之外的其他库,包括哈希、最长前缀匹配 (LPM) 和环库。 提供示例应用程序以帮助向用户展示如何使用 DPDK 的各种功能。
The DPDK implements a run to completion model for packet processing, where all resources must be allocated prior to calling Data Plane applications, running as execution units on logical processing cores. The model does not support a scheduler and all devices are accessed by polling. The primary reason for not using interrupts is the performance overhead imposed by interrupt processing.
DPDK 为数据包处理实现了一个运行到完成的模型,其中所有资源必须在调用数据平面应用程序之前分配,作为逻辑处理核心上的执行单元运行。 该模型不支持调度程序,所有设备均通过轮询访问。 不使用中断的主要原因是中断处理带来的性能开销。
In addition to the run-to-completion model, a pipeline model may also be used by passing packets or messages between cores via the rings. This allows work to be performed in stages and may allow more efficient use of code on cores.
除了运行到完成模型之外,还可以通过环在内核之间传递数据包或消息来使用流水线模型。 这允许分阶段执行工作,并且可以更有效地使用内核上的代码。
环境抽象层 (EAL) 负责获取对硬件和内存空间等低级资源的访问。 它提供了一个通用接口,可以对应用程序和库隐藏环境细节。 初始化例程负责决定如何分配这些资源(即内存空间、设备、计时器、控制台等)。
环境抽象层 (EAL) 提供了一个通用接口,可对应用程序和库隐藏环境细节。 EAL提供的服务有:
- DPDK loading and launching
- Support for multi-process and multi-thread execution types
- Core affinity/assignment procedures
- System memory allocation/de-allocation
- Atomic/lock operations
- Time reference
- PCI bus access
- Trace and debug functions
- CPU feature identification
- Interrupt handling
- Alarm operations
- Memory management (malloc)
DPDK 加载和启动:DPDK 及其应用程序链接为单个应用程序,必须通过某种方式加载。 Core Affinity/Assignment Procedures:EAL 提供了将执行单元分配给特定内核以及创建执行实例的机制。 系统内存预留:EAL 有助于预留不同的内存区域,例如,用于设备交互的物理内存区域。 跟踪和调试功能:日志、dump_stack、panic 等。 实用函数:libc 中未提供的自旋锁和原子计数器。 CPU 功能识别:在运行时确定是否支持特定功能,例如 Intel® AVX。 确定当前 CPU 是否支持编译二进制文件的功能集。 中断处理:用于注册/取消注册特定中断源的回调的接口。 警报功能:用于设置/删除要在特定时间运行的回调的接口。
The ring structure provides a lockless multi-producer, multi-consumer FIFO API in a finite size table. It has some advantages over lockless queues; easier to implement, adapted to bulk operations and faster. A ring is used by the Memory Pool Manager (librte_mempool) and may be used as a general communication mechanism between cores and/or execution blocks connected together on a logical core.
环形结构在有限大小的表中提供无锁的多生产者、多消费者 FIFO API。 它比无锁队列有一些优势; 更易于实施,适应批量操作且速度更快。 环由内存池管理器 (librte_mempool) 使用,可用作核心和/或在逻辑核心上连接在一起的执行块之间的通用通信机制。
The Memory Pool Manager is responsible for allocating pools of objects in memory. A pool is identified by name and uses a ring to store free objects. It provides some other optional services, such as a per-core object cache and an alignment helper to ensure that objects are padded to spread them equally on all RAM channels.
内存池管理器负责在内存中分配对象池。 池由名称标识并使用环来存储空闲对象。 它提供了一些其他可选服务,例如每核对象缓存和对齐助手,以确保填充对象以将它们平均分布在所有 RAM 通道上。
mbuf 库提供了创建和销毁缓冲区的功能,DPDK 应用程序可以使用这些缓冲区来存储消息缓冲区。 消息缓冲区在启动时创建,并使用 DPDK 内存池库存储在内存池中。
该库提供了一个 API 来分配/释放 mbuf,操作用于承载网络数据包的数据包缓冲区。
网络数据包缓冲区管理在 Mbuf 库中进行了描述。
Timer Manager (librte_timer)
该库为 DPDK 执行单元提供定时器服务,提供异步执行功能的能力。 它可以是周期性的函数调用,或者只是一次调用。 它使用环境抽象层 (EAL) 提供的计时器接口来获取精确的时间参考,并且可以根据需要在每个内核的基础上启动。
Ethernet* Poll Mode Driver Architecture
DPDK 包括用于 1 GbE、10 GbE 和 40GbE 的轮询模式驱动程序 (PMD),以及半虚拟化 virtio 以太网控制器,这些控制器设计用于在没有异步、基于中断的信号机制的情况下工作。
Packet Forwarding Algorithm Support
DPDK包含了Hash(librte_hash)和Longest Prefix Match(LPM,librte_lpm)库来支持相应的包转发算法。
有关详细信息,请参阅哈希库和 LPM 库。
librte_net
librte_net 库是 IP 协议定义和便捷宏的集合。 它基于 FreeBSD* IP 堆栈的代码,包含协议编号(用于 IP 标头)、IP 相关宏、IPv4/IPv6 标头结构以及 TCP、UDP 和 SCTP 标头结构。
Ring Library
环允许队列的管理。 rte_ring 没有无限大小的链表,而是具有以下属性:
- FIFO
- Maximum size is fixed, the objects are stored in a table
- Objects can be pointers or elements of multiple of 4 byte size
- Lockless implementation
- Multi-consumer or single-consumer dequeue
- Multi-producer or single-producer enqueue
- Bulk dequeue - Dequeues the specified count of objects if successful; otherwise fails
- Bulk enqueue - Enqueues the specified count of objects if successful; otherwise fails
- Burst dequeue - Dequeue the maximum available objects if the specified count cannot be fulfilled
- Burst enqueue - Enqueue the maximum available objects if the specified count cannot be fulfilled
先进先出 最大大小是固定的,对象存储在表中 对象可以是指针或 4 字节大小的倍数的元素 无锁实现 多消费者或单消费者出队 多生产者或单一生产者排队 批量出队 - 如果成功,则出队指定数量的对象; 否则失败 批量入队 - 如果成功,则将指定数量的对象入队; 否则失败 突发出队 - 如果无法满足指定的计数,则出队最大可用对象 突发入队 - 如果无法满足指定的计数,则将最大可用对象入队
The advantages of this data structure over a linked list queue are as follows:
- Faster; only requires a single 32 bit Compare-And-Swap instruction instead of several pointer size Compare-And-Swap instructions.
- Simpler than a full lockless queue.
- Adapted to bulk enqueue/dequeue operations. As objects are stored in a table, a dequeue of several objects will not produce as many cache misses as in a linked queue. Also, a bulk dequeue of many objects does not cost more than a dequeue of a simple object.
The disadvantages:
- Size is fixed
- Having many rings costs more in terms of memory than a linked list queue. An empty ring contains at least N objects.
A simplified representation of a Ring is shown in with consumer and producer head and tail pointers to objects stored in the data structure
这种数据结构相对于链表队列的优势如下:
快点; 只需要一个 32 位比较和交换指令,而不是几个指针大小的比较和交换指令。 比完整的无锁队列更简单。 适用于批量入队/出队操作。 由于对象存储在表中,因此多个对象的出队不会产生与链接队列中一样多的缓存未命中。 此外,许多对象的批量出列不会比简单对象的出列花费更多。 缺点:
尺寸固定 与链表队列相比,拥有多个环在内存方面的成本更高。 一个空环至少包含 N 个对象。 Ring 的简化表示如图所示,消费者和生产者的头部和尾部指针指向存储在数据结构中的对象
8.1. References for Ring Implementation in FreeBSD*
The following code was added in FreeBSD 8.0, and is used in some network device drivers (at least in Intel drivers):
8.1. FreeBSD 中环实现的参考资料* 以下代码是在 FreeBSD 8.0 中添加的,并用于某些网络设备驱动程序(至少在 Intel 驱动程序中):
FreeBSD 中的 bufring.h FreeBSD 中的 bufring.c
8.2. Lockless Ring Buffer in Linux*
The following is a link describing the Linux Lockless Ring Buffer Design.
8.2. Linux* 中的无锁环形缓冲区 以下是描述 Linux Lockless Ring Buffer Design 的链接。
-
Cache子系统
- 一级Cache:4个指令周期,分为数据cache和指令cache,一般只有几十KB
- 二级Cache:12个指令周期,几百KB到几MB
- 三级Cache:26-31个指令周期,几MB到几十MB
- TLB Cache:缓存内存中的页表项,减少CPU开销
如何把内存中的内容放到cache中呢?这里需要映射算法和分块机制。当今主流块大小是64字节。
硬件Cache预取(Netburst为例):
- 只有两次
cache miss才能激活预取机制,且2次的内存地址偏差不超过256或512字节 - 一个4KB的page内只定义一条
stream - 能同时独立的追踪8条
stream - 对4KB边界之外不进行预取
- 预取的数据放在二级或三级cache中
- 对
strong uncacheable和write combining内存类型不预取
硬件预取不一定能够提升性能,所以
DPDK还借助软件预取尽量将数据放到cache中。另外,DPDK在定义数据结构的时候还保证了cache line对齐。cache一致性
- 原则是避免多个核访问同一个内存地址或数据结构
- 在数据结构上:每个核都有独立的数据结构
- 多个核访问同一个网卡:每个核都创建单独的接收队列和发送队列
Huge Page
hugetlbfs有两个好处:
- 第一是使用hugepage的内存所需的页表项比较少,对于需要大量内存的进程来说节省了很多开销,像oracle之类的大型数据库优化都使用了大页面配置;
- 第二是TLB冲突概率降低,TLB是cpu中单独的一块高速cache,采用hugepage可以大大降低TLB miss的开销。
DPDK目前支持了2M和1G两种方式的hugepage。通过修改默认/etc/grub.conf中hugepage配置为default_hugepagesz=1G hugepagesz=1G hugepages=32 isolcpus=0-22,然后通过mount –t hugetlbfs nodev /mnt/huge就将hugepage文件系统hugetlbfs挂在/mnt/huge目录下,然后用户进程就可以使用mmap映射hugepage目标文件来使用大页面了。测试表明应用使用大页表比使用4K的页表性能提高10%-15%。
Linux系统启动后预留大页的方法
- 非NUMA系统:
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages - NUMA系统:
echo 1024 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages - 对于1G的大页,必须在系统启动的时候指定,不能动态预留
Data Direct I/O (DDIO)
DDIO使得外部网卡和CPU通过LLC cache (最后一级缓存叫LLC(Last Level Cache), LLC的后面就是内存)直接交换数据,绕过了内存,增加了CPU处理报文的速度。
在Intel E5系列产品中,LLC Cache的容量提高到了20MB。

NUMA
NUMA来源于AMD Opteron微架构,处理器和本地内存之间有更小的延迟和更大的带宽;每个处理器还可以有自己的总线。处理器访问本地的总线和内存时延迟低,而访问远程资源时则要高。

DPDK充分利用了NUMA的特点
Per-core memory,每个核都有自己的内存,一方面是本地内存的需要,另一方面也是为了cache一致性- 用本地处理器和本地内存处理本地设备上产生的数据
|
|
CPU核心的几个概念:
- 处理器核数(
cpu cores):每个物理CPUcore的个数 - 逻辑处理器核心数(
siblings):单个物理处理器超线程的个数 - 系统物理处理器封装ID(
physical id):也称为socket插槽,物理机处理器封装个数,物理CPU个数 - 系统逻辑处理器ID(
processor):逻辑CPU数,是物理处理器的超线程技术
CPU亲和性
将进程与CPU绑定,提高了Cache命中率,从而减少内存访问损耗。CPU亲和性的主要应用场景为
- 大量计算场景
- 运行时间敏感、决定性的线程,即实时线程
相关工具
sched_set_affinity()、sched_get_affinity()内核函数taskset命令isolcpus内核启动参数:CPU绑定之后依然是有可能发生线程切换,可以借助isolcpus=2,3将cpu从内核调度系统中剥离。
DPDK中的CPU亲和性
DPDK中lcore实际上是EAL pthread,每个EAL pthread都有一个Thread Local Storage的_lcore_id,_lcore_id与CPU ID是一致的。注意虽然默认是1:1关系,但可以通过--lcores='<lcore_set>@<cpu_set>'来指定lcore的CPU亲和性,这样可以不是1:1的,也就是多个lcore还是可以亲和到同一个的核,这就需要注意调度的情况(以非抢占式无锁rte_ring为例):
- 单生产者、单消费者模式不受影响
- 多生产者、多消费者模式,调度策略为
SCHED_OTHER时,性能会有所影响 - 多生产者、多消费者模式,调度策略为
SCHED_FIFO/SCHED_RR,会产生死锁
而在具体实现流程如下所示:
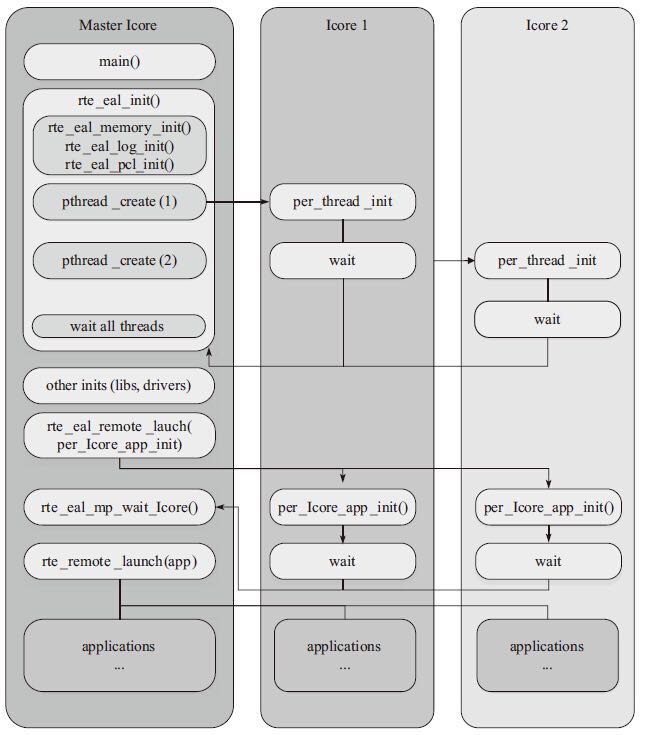
- DPDK通过读取
/sys/devices/system/cpu/cpuX/目录的信息获取CPU的分布情况,将第一个核设置为MASTER,并通过eal_thread_set_affinity()为每个SLAVE绑定CPU - 不同模块要调用
rte_eal_mp_remote_launch()将自己的回调函数注册到DPDK中(lcore_config[].f) - 每个核最终调用
eal_thread_loop()->回调函数来执行真正的逻辑
指令并发
借助SIMD(Single Instruction Multiple Data,单指令多数据)可以最大化的利用一级缓存访存的带宽,但对频繁的窄位宽数据操作就有比较大的副作用。DPDK中的rte_memcpy()在Intel处理器上充分利用了SSE/AVX的特点:优先保证Store指令存储的地址对齐,然后在每个指令周期指令2条Load的特新弥补一部分非对齐Load带来的性能损失。
- 原文作者:晓兵
- 原文链接:https://logread.cn/post/dpdk/dpdk/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。