Linux内核与DPDK-HTTP 性能对决(Linux Kernel vs DPDK: HTTP Performance Showdown)[译]
概述
在这篇文章中,我将使用一个简单的 HTTP 基准测试在 Linux 内核的网络堆栈和由 DPDK 提供支持的内核旁路堆栈之间进行正面性能比较。 我将使用 Seastar 运行我的测试,Seastar 是一个用于构建高性能服务器应用程序的 C++ 框架。 Seastar 支持构建使用 Linux 内核或 DPDK 进行网络连接的应用程序,因此它是进行此比较的完美框架。
我将以我之前的性能调优帖子中的许多想法和技术为基础,因此在继续之前至少阅读概述部分可能是值得的。
为内核辩护
绕过内核可以打开一个全新的高吞吐量和低延迟的世界。 根据您询问的对象,您可能会听说绕过内核会使性能提高 3-5 倍。 然而,大多数这些比较都是在内核方面没有进行太多优化的情况下完成的。
Linux 内核旨在快速,但它也被设计为多用途,因此默认情况下它并未针对高速网络进行完美优化。 另一方面,像 DPDK 这样的内核绕过技术对网络性能采取一种专一的方法。 整个网络接口专用于单个应用程序,并使用积极的繁忙轮询(busy polling)来实现高吞吐量和低延迟。 在这篇文章中,我想看看当经过微调的内核/应用程序在无限制的战斗中与内核旁路正面交锋时,性能差距会是什么样子。
DPDK 拥护者建议绕过内核是必要的,因为内核“慢”,但实际上 DPDK 的很多性能优势并非来自绕过内核,而是来自强制执行某些约束。 事实证明,这些优势中的许多都可以在仍然使用内核的情况下实现。 通过关闭一些功能,打开其他功能,并相应地调整应用程序,可以实现接近内核旁路速度的性能。
以下是一些也可以使用内核完成的 DPDK 策略:
忙轮询(中断仲裁(Interrupt moderation) + net.core.busy_poll=1) 完美的本地化(RSS + XPS + SO_REUSEPORT_CBPF) 简化的 TCP/IP 子系统(禁用 iptables/系统调用审计/AF_PACKET 套接字) 内核绕过技术仍然具有的一个优势是,它们避免了在用户态和内核之间来回转换(和复制数据)所产生的系统调用开销。 所以DPDK应该还是有整体优势的,但问题是优势有多大。
免责声明
这个探索性项目的工作由 ScyllaDB, Inc 的人员赞助,他们是开源 Seastar 框架的主要管理者,也是 P99 CONF 的组织者。 去年我在 P99 CONF 上发言后,他们联系了我,看看是否有任何我们可以探索的共同感兴趣的领域。 我的上一个实验让我对进行内核与 DPDK 的摊牌感到好奇,而 Seastar 完全符合要求,所以这篇文章就是这种参与的结果。 所有技术讨论都在他们的公共 Slack 频道和邮件列表中进行。
路线图
这篇文章很长,所以这里有一个高级大纲,以防您想跳转到感兴趣的特定领域。
入门
编译海星 Building Seastar 基准设置
DPDK 设置和优化
AWS 上的 DPDK DPDK优化
内核堆栈优化
基线内核性能 操作系统级别优化 完美本地化和繁忙的轮询(需要多次尝试才能使它正常工作)Perfect Locality and Busy Polling 常量上下文切换 最好是RECV 记得冲刷 flush
结果、注意事项和好奇心
最终获胜者是… DPDK 注意事项 推测执行缓解措施
结束
结论 附录
在原文中单击右上角的菜单图标将打开一个目录,以便您可以轻松跳转到特定部分。
编译seastar
最初构建 Seastar 时我遇到了一些挑战。 我想使用 Amazon Linux 2,因为我对它非常熟悉,但很明显,我正在与过时的依赖项进行一场注定失败的战斗。 我切换到香草 CentOS 8 并设法让它运行,尽管有一些问题,但我仍然觉得我的基础不够坚实。 在与 CentOS Stream 9 短暂接触后,我在公共 Slack 频道寻求帮助,我被指向 Fedora 34 的方向作为构建最新版本代码库的最佳操作系统。
实际上,我的大部分研究和测试都是使用 Fedora 34(内核 5.15)进行的,但是尽管 Fedora 的前沿更新可能很棒,但有时前沿会成为最前沿。 当我决定从头开始重现我的结果时,我意识到最新的 Fedora 34 更新正在将内核从 5.11 直接升级到 5.16 版。 不幸的是,内核 5.16 触发了我的测试性能回归,所以我需要一个替代方案。
事实证明,Amazon Linux 2022 基于 Fedora 34,但具有更保守的内核更新策略,选择坚持使用 5.15 LTS 版本,因此我选择 AL 2022 作为这些测试的新基础操作系统,它有一些修正历史,在接下来的帖子中,我会假装我一直在使用它。
HTTP服务器
我开始使用 Seastar 的内置 HTTP 服务器 (httpd) 进行测试,但我决定从 httpd 降低一个级别,使用一个简单的 TCP 服务器,它只是假装是一个 HTTP 服务器。 服务器只是发回一个固定的 HTTP 响应,而不做任何解析或路由。 这简化了我的分析,并更清楚地突出了我所做的每项更改的影响。 特别是我想从等式中消除 Seastar 的内置 HTTP 解析器。 在我删除它之前,性能会根据客户端发送的 HTTP 标头数量而有很大差异。 因此,我没有深入了解那里发生了什么,而是决定使用我简单的 tcp_httpd 服务器来替代。
源代码
基于我为这个项目所做的工作,我在主要的 Seastar 存储库上打开了一些 PR,但是大多数更改不适合上游,因为它们依赖于 epoll,并且当前的开发现在集中在 aio 和 io_uring 上。 本文中使用的所有补丁都可以在我的 GitHub 上的 Seastar 存储库(https://github.com/talawahtech/seastar/tree/http-performance/)中找到。
基准设置
这是 AWS 基准测试设置的基本概述。 我使用 Techempower JSON 序列化测试作为本次实验的参考基准。 https://www.techempower.com/benchmarks/#section=intro https://github.com/TechEmpower/FrameworkBenchmarks/wiki/Project-Information-Framework-Tests-Overview#json-serialization
硬件
服务器:4 vCPU c5n.xlarge 实例 客户端:16 vCPU c5n.4xlarge 实例(如果我尝试使用较小的实例大小,客户端就会成为瓶颈) 网络:服务器和客户端位于集群归置组中的同一可用区(use2-az1)
软件
操作系统:Amazon Linux 2022(内核 5.15) 服务器:我的简单 tcp_httpd 服务器:sudo ./tcp_httpd –reactor-backend epoll 客户:我对流行的 HTTP 基准测试工具 wrk 进行了一些修改,并将其昵称为 twrk。 twrk 在短时间、低延迟的测试运行中提供更一致的结果。 wrk 的标准版本应该在吞吐量方面产生类似的数字,但 twrk 允许改进 p99 延迟,并增加了对显示 p99.99 延迟的支持。
基准配置
我使用以下参数从客户端手动运行 twrk: 无流水线 256个连接 16 个线程(每个 vCPU 1 个),每个线程固定到一个 vCPU 统计数据收集开始前 1 秒预热,然后测试运行 5 秒
|
|
DPDK on AWS
让 Seastar 和 DPDK 在 AWS 上运行绝非易事。 AWS ENA 驱动程序的 DPDK 文档最近有了很大的改进,但我开始时有点粗糙,很难找到将 Seastar 与 DPDK 一起使用的工作示例。 值得庆幸的是,在 Slack 频道的帮助和我顽固的坚持之间,我能够让事情顺利进行。
对于那些希望这样做的人来说,以下是一些亮点:
DPDK 需要能够接管整个网络接口,因此除了用于通过 SSH 连接实例的主接口(eth0/ens5)之外,您还需要附加一个专用于 DPDK 的辅助接口(eth1/ens6) .
DPDK 依赖于两个可用的内核框架之一,用于将设备直接访问公开到用户空间、VFIO 或 UIO。 VFIO 是推荐的选择,它在最近的内核上默认可用。 默认情况下,VFIO 依赖于硬件 IOMMU 支持以确保以安全的方式进行直接内存访问,但是 IOMMU 支持仅适用于 *.metal EC2 实例。 对于非金属实例,VFIO 通过在加载内核模块时设置 enable_unsafe_noiommu_mode=1 来支持在没有 IOMMU 的情况下运行。
Seastar 使用 DPDK 19.05,此时有点过时。 AWS ENA 驱动程序有一组适用于 DPDK 19.05 的补丁,必须应用这些补丁才能让 Seastar 在 AWS 上运行。 为了方便起见,我将补丁反向移植到我的 DPDK 分支。
最后但同样重要的是,我在 DPDK/ENA 驱动程序中遇到了一个错误,该错误导致出现以下错误消息:运行时错误:ena_queue_start():无法填充 rx 环。 这个问题去年在 DPDK 代码库中得到修复,因此我将更改反向移植到我的 DPDK 分支中。
使用 tcp_httpd 应用程序,我使用 DPDK 作为底层网络堆栈运行我的基准测试:
|
|
DPDK 性能一开始就令人印象深刻: 1.19M req/s !!!
初始火焰图
火焰图提供了一种独特的方式来可视化 CPU 使用率并识别您的应用程序最常用的代码路径。 它们是一种强大的优化工具,因为它们可以让您快速识别和消除瓶颈。 单击下图将打开由 Flamegraph 工具生成的原始 SVG 文件。 这些 SVG 是交互式的。 您可以单击一个细分以深入了解更详细的视图,或者您可以搜索(Ctrl + F 或单击右上角的链接)函数名称。 请注意,每个完整的火焰图都捕获了四个几乎相同的堆栈,代表 4 个反应器(reactor)线程(每个 vCPU 一个),但在整个帖子中,我们将主要关注分析单个反应器/vCPU 的数据。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-initial-app-unoptimized-os.svg
火焰图分析
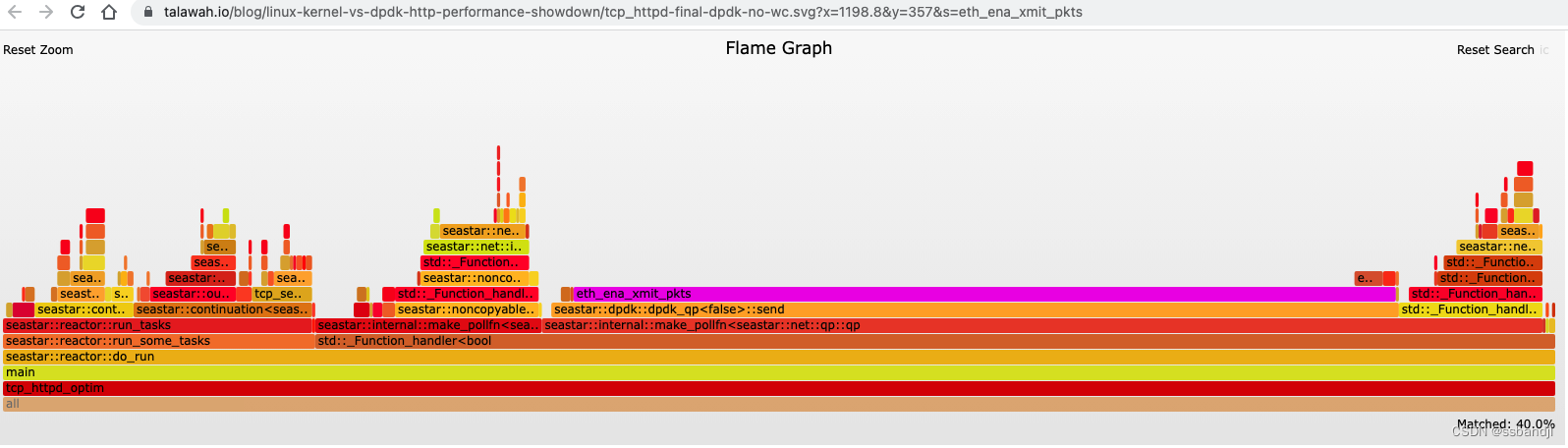
快速查看一下火焰图就足以看出 eth_ena_xmit_pkts 函数看起来大得可疑,占整个火焰图的 53.1%。
https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-dpdk-no-wc.svg?x=1198.8&y=357&s=eth_ena_xmit_pkts
DPDK优化
在第 5 代以上的实例上,ENA 硬件/驱动程序支持 LLQ(低延迟队列 Low Latency Queue)模式以提高性能。 使用这些实例时,强烈建议您启用相应内核模块(VFIO 或 UIO)的写组合(write combining feature)功能,否则,性能将因 PCI 事务缓慢而受到影响。
默认情况下,VFIO 模块不支持写入组合,但 ENA 团队提供了一个补丁和一个脚本来自动执行向内核模块添加 WC 支持的过程。 我最初在使用内核 5.15 时遇到了一些问题,但 ENA 团队对修复这些问题反应迅速。 该团队最近还表示他们打算将 VFIO 补丁上游,这有望在未来让事情变得更加轻松。
|
|
启用写入组合可将性能从 1.19M req/s 提高到 1.51M req/s,性能提升 27%
火焰图分析
我们的火焰图现在看起来更加平衡,eth_ena_xmit_pkts 从火焰图的 53.1% 下降到仅仅 6.1%
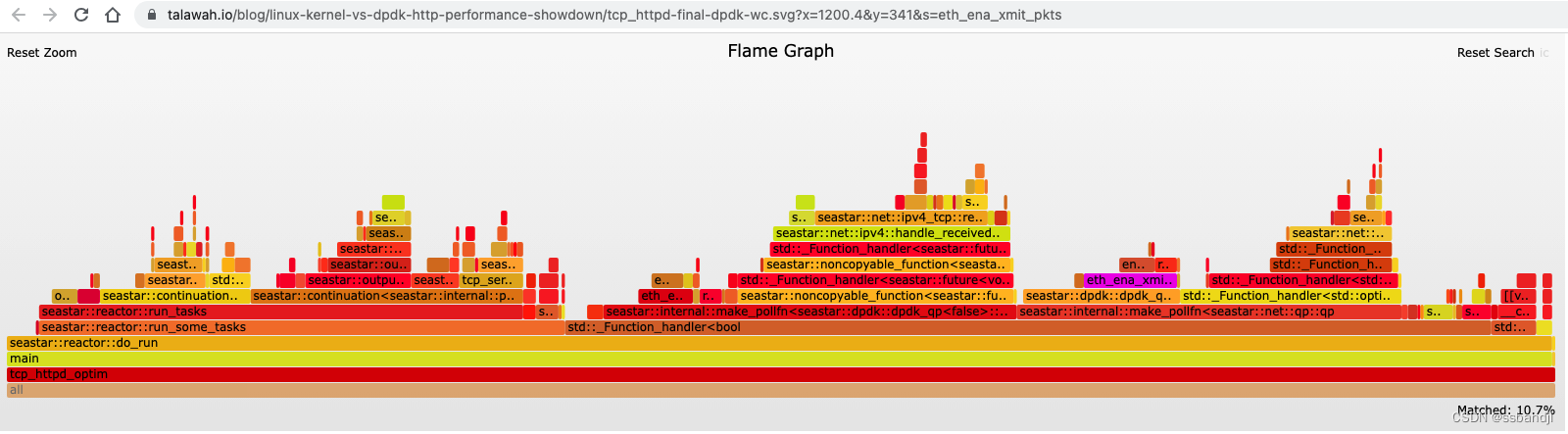 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-dpdk-wc.svg?x=1200.4&y=341&s=eth_ena_xmit_pkts
https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-dpdk-wc.svg?x=1200.4&y=341&s=eth_ena_xmit_pkts
一项艰巨的任务
DPDK 以绝对巨大的表现打破了挑战。 在 4 个 vCPU 实例上每秒 1.51M 请求是巨大的。 内核甚至可以接近吗?
基线内核性能
从未修改的 AL 2022 AMI 开始,tcp_httpd 性能开始时约为 358k req/s。 从绝对意义上讲,这确实非常非常快,但相比之下就显得平庸了。
|
|
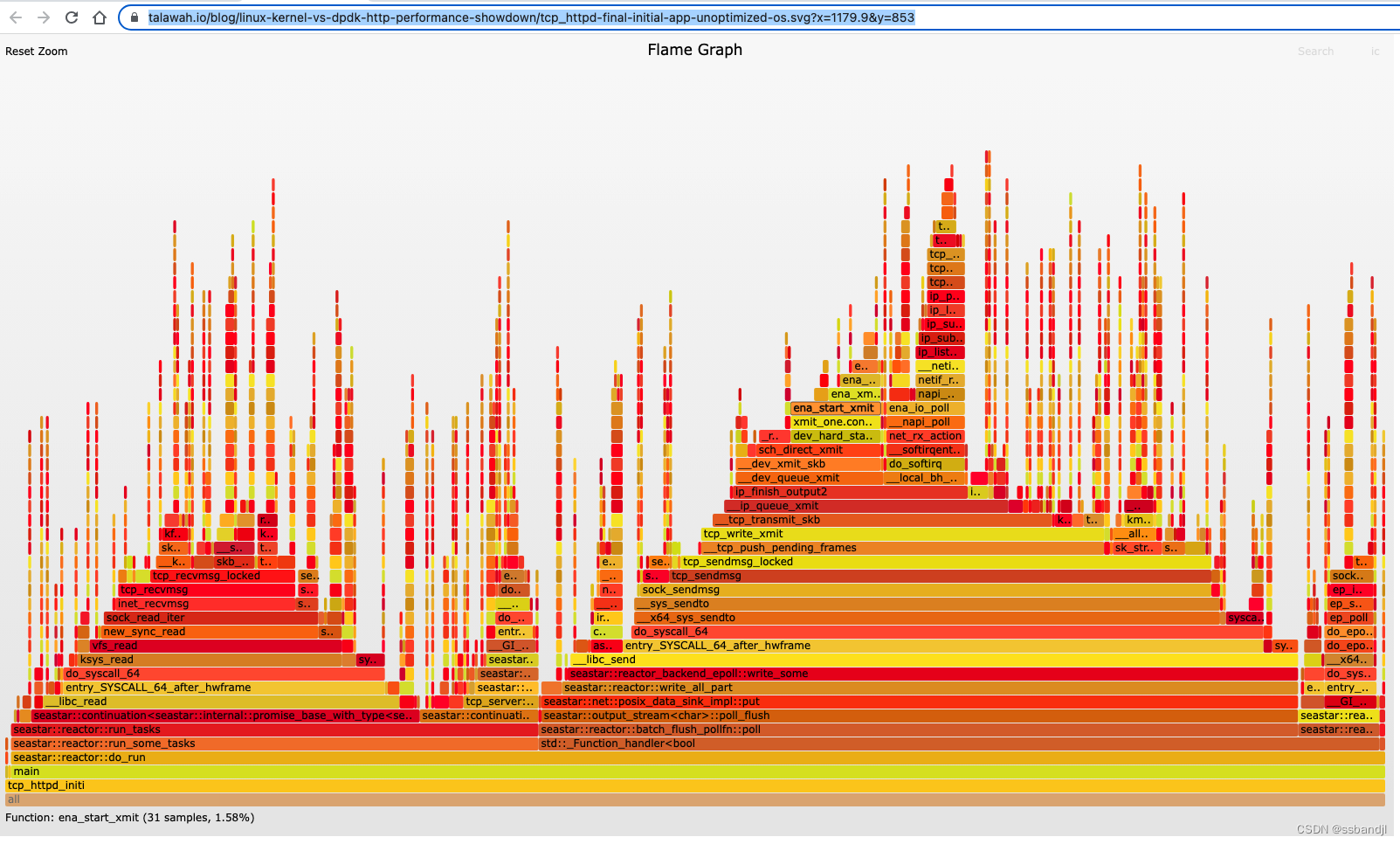
操作系统级别优化
我不会详细介绍我所做的特定 Linux 更改。 从较高的层面来看,这些更改在本质上与我在上一篇文章(https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/)中对 Amazon Linux 2/kernel 4.14 所做的调整非常相似。 也就是说,从内核 4.14 和 5.15 开始,此工作负载实际上出现了显着的性能退化,并且需要做大量工作才能使性能恢复到标准水平。 但我现在想专注于内核与 DPDK 的比较,所以我将把这些细节留到另一天,另一篇文章。 以下是所用操作系统优化的高级概述:
禁用推测执行缓解措施(Disable Speculative Execution Mitigations): https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#_2-speculative-execution-mitigations 配置 RSS 和 XPS 以获得完美的本地化(Configure RSS and XPS for perfect locality): https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#receive-side-scaling-rss 中断仲裁和忙轮询(Interrupt Moderation and Busy Polling): https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#_6-interrupt-optimizations 禁用原始/数据包套接字(Disable Raw/Packet Sockets )(仅供参考,这次它不是同一个爱管闲事的邻居):https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#_7-the-case-of-the-nosy-neighbor GRO、拥塞控制和静态中断调节(GRO, Congestion Control, and Static Interrupt Moderation): https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#_9-this-goes-to-twelve 一些新的优化 我们的操作系统优化将吞吐量从 358k req/s 提升到了惊人的 726k req/s。 性能提升 103%。
|
|
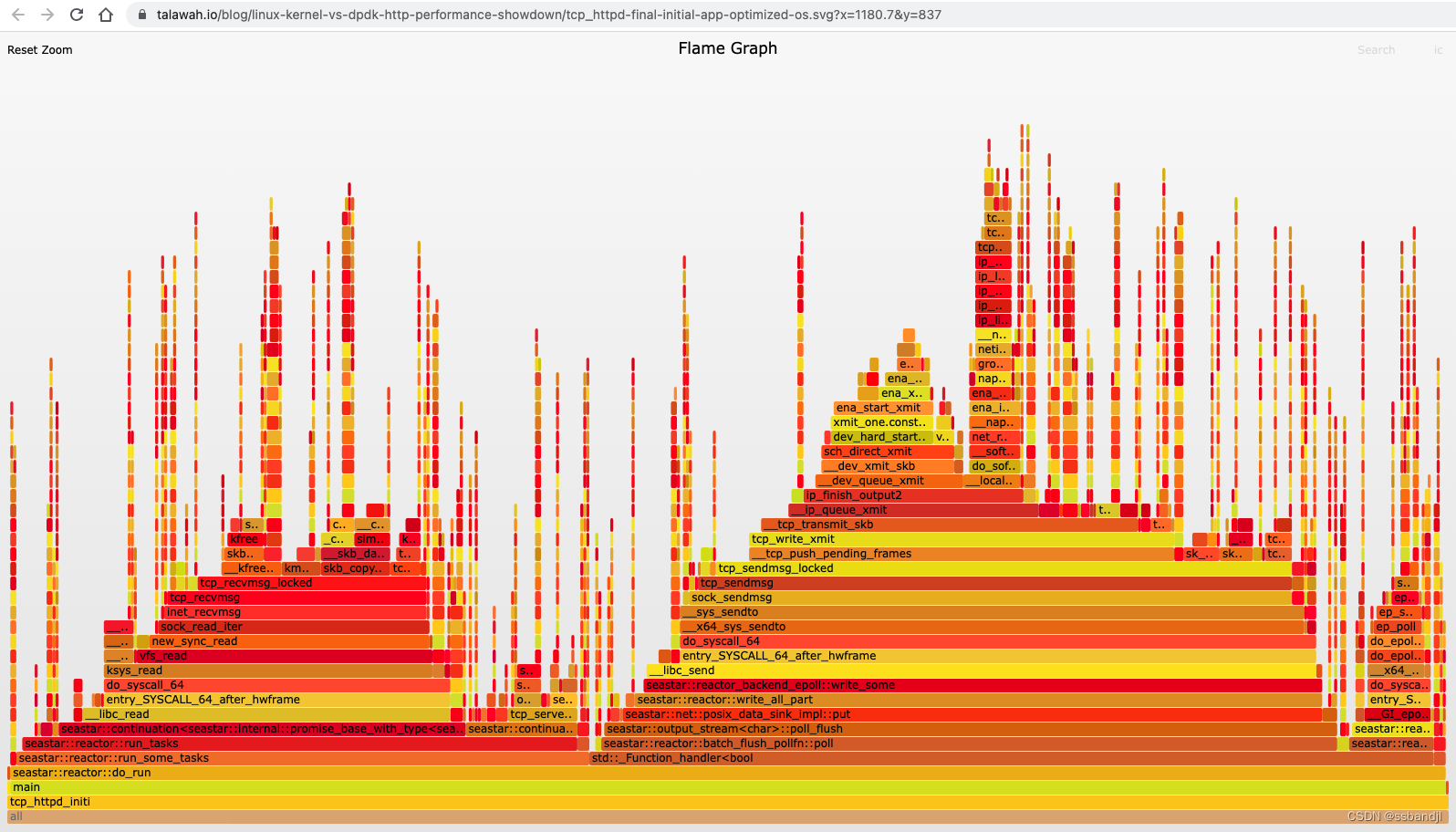
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Perfect Locality and Busy Polling
在正确配置应用程序之前,操作系统级别的更改以启用完美的位置/繁忙轮询并没有太大影响。 我的下一步是将 SO_ATTACH_REUSEPORT_CBPF(https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#so-attach-reuseport-cbpf) 支持添加到我的 Seastar 分支中,以便完成完美的位置设置。
|
|
吞吐量从 736k req/s 变为令人印象深刻的 741k req/s。 2% 的性能提升远低于我对这一变化的预期。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-enable-so_attach_reuse_port_cbpf.svg?x=1185.7&y=837
{kind=link}
火焰图分析
火焰图显示繁忙轮询的证据为零。 完美的局部性和繁忙的轮询在良性循环中协同工作,因此缺少繁忙的轮询是我们的设置存在问题的有力指标。 完美的局部性需要配置操作系统和应用程序,以便一旦网络数据包到达给定队列,所有进一步的处理都由相同的 vCPU/队列筒仓处理传入和传出数据。 这意味着进程/线程的启动顺序,以及它们固定到的 CPU 必须受到控制。
Perfect Locality and Busy Polling: Take two
我创建了一个 bftrace 脚本来仔细查看实际发生的情况。 该脚本将 kprobes 附加到 reuseport_alloc() 和 reuseport_add_sock() 以跟踪进程/线程启动顺序和 cpu 亲和力。 结果马上就暴露了问题。 即使反应器线程按顺序启动(tcp_httpd/reactor-0、reactor-1、reactor-2、reactor-3),CPU pinning 也是乱序的(0、2、1、3)。
|
|
进一步的调查显示,Seastar 使用 hwloc 来了解硬件拓扑并相应地进行优化。 但是默认的 CPU 分配策略对于我们的用例来说并不是最佳的,所以在邮件列表中提出这个问题后,我在我的分支中添加了一个函数,将反应堆分片 ID 和 CPU ID 之间的映射公开给在 Seastar 上构建的应用程序。
我修改了 tcp_httpd 以确保 cpu id 和 socket id 匹配。 这导致了我的 bpftrace 脚本的预期输出。
|
|
Performance improves slightly, but still leaves a lot to be desired.
|
|
这次性能提高了 6%,但仍远低于预期。
火焰图分析
火焰图也没有显示太多变化,仍然没有繁忙的轮询发生,所以有其他地方不对劲。 我研究了我的性能分析工具包,看看我是否能弄清楚还发生了什么。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-optimize-reuse_port_cbpf.svg?x=1190.6&y=789
{kind=link}
Impatiently Waiting
我能够使用 libreactor 作为参考点,了解完全优化的基于 epoll 的 HTTP 服务器的行为方式,并将其与 tcp_httpd 进行对比。 运行 10 秒的 syscount 跟踪 (syscount -d 10),同时为 libreactor 和 tcp_httpd 运行基准测试产生了一些有启发性的结果:
libreactor
|
|
tcp_httpd
|
|
对于 libreactor,前两个系统调用是发送/接收,epoll_wait 排在第三位。 与 tcp_httpd 相反,epoll_pwait 是第一个系统调用。 这是一个很好的指标,表明我需要查看在 Seastar 代码库中如何调用 epoll_pwait。
epoll_pwait 系统调用等待与文件描述符相关的事件。 在我们的例子中,我们专门处理套接字文件描述符(代表 TCP 连接),每个事件都表示准备好发送或接收数据。
原始的 epoll_(p)wait 系统调用可以被认为是为超时参数取 3 种类型的值
-1:系统调用无限期地等待一个事件 0:无论是否有任何事件准备好,系统调用都会立即返回 n:系统调用等待直到文件描述符传递事件或 n 毫秒过去 libreactor 使用完全围绕 epoll 构建的相对简单的反应器引擎,因此它可以无限期地等待下一个事件。 另一方面,Seastar 要复杂一些。 Seastar 支持多种不同的高分辨率计时器、轮询函数和跨反应器消息队列; 并且它试图对任务预计运行多长时间实施某些保证。 在主 do_run 循环中,Seastar 调用 epoll_pwait,超时为 0(它根本不等待),这就是我们没有看到任何繁忙轮询发生的原因。 使用无限期超时调用 epoll_pwait 对 Seastar 来说是行不通的,即使使用 epoll_pwait 最小值 1ms 调用它也可能有点太长了。 Seastar 的任务应在单个周期内运行多长时间 (task-quota-ms) 的默认值为 0.5 (500us),这一事实证明了这一点。
为了在框架的延迟预期和我的性能目标之间取得平衡,我决定使用相对较新的 epoll_pwait2 系统调用。 epoll_pwait2 等同于 epoll_pwait,但超时参数可以指定为纳秒分辨率。 我选择 100us 的超时值作为性能和延迟保证之间的良好平衡。 新的系统调用从内核 5.11 开始可用,但相应的 glibc 包装器直到 glibc 2.35 才可用,而 Amazon Linux 2022 随 glibc 2.34 一起提供。 为了解决这个问题,我破解了一个名为 epoll_pwait_us 的包装函数,并更新了我的 Seastar 分支以使用值 100 调用它。
|
|
性能从 788k req/s 移动到 915k req/s,稳步增长 16%。
火焰图分析
查看火焰图,您可以清楚地看到繁忙的轮询终于开始了,查看我们的系统调用计数,我们可以看到预期的模式出现了。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-epoll_wait-100us.svg?x=1192.4&y=773
{kind=link}
tcp_httpd
|
|
Constant Context Switching
我继续使用更多 perf 工具比较 tcp_httpd 和 libreactor,看看我是否能发现更多异常。 果然,使用 sar -w 1 来监视上下文切换为 tcp_httpd 产生了一些令人惊讶的数字。
|
|
|
|
在不放大的情况下查看火焰图,我注意到对于每个反应器线程,Seastar 创建了一个匹配的定时器线程,名称为 timer-0、timer-1 等。起初我没有太注意它们,因为我没有明确地 设置任何计时器,它们在火焰图上几乎看不到,但鉴于上下文切换数字,我决定仔细查看。
对于每个 reactor/cpu 核心,start_tick() 使用 task_quota_timer_thread_fn() 函数启动一个线程。 该函数等待反应器的 _task_quota_timer 到期,然后通过调用 request_preemption() 中断主线程。 这样做是为了确保主线程上的任务不会在没有抢占的情况下运行超过 X 毫秒而占用资源。 但是对于我们的特定工作负载,它会导致过多的上下文切换和坦克性能。 我们想要做的是将它设置得足够长,以便 reactor::run_some_tasks() 可以完成所有任务并重置抢占而不会被中断。 应该注意的是,Seastar 的默认 aio 后端似乎使用了一些特定于 aio 的抢占功能来处理任务配额,因此这种特殊行为仅限于 epoll 后端。
Seastar 允许用户通过命令行传入一个值来设置 –task-quota-ms。 默认值为 0.5,但我发现 10 毫秒对于此工作负载来说是一个更合理的值。
tcp_httpd 与 –task-quota-ms 10
|
|
每秒上下文切换次数从 17k 急剧下降到 1.3k
|
|
吞吐量从 915k req/s 提高到 964k req/s,提高了 5.3%
火焰图分析
火焰图中的变化非常微妙。 如果你缩小到“全部”视图,然后搜索计时器——你会看到最右边的一小部分从前一个火焰图的 0.7% 变为当前火焰图的 0.1%。 火焰图非常有用,但它们并不总是以成比例的方式捕捉性能影响。 有时您必须在 perf 工具箱中翻找,以找到合适的工具来发现异常。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-epoll_wait-100us-task-quota-ms-10.svg?x=1198.8&y=885
{kind=link}
最好是RECV
这是我在优化 libreactor 时想到的一个简单修复。 使用套接字时,使用 Linux 的接收/发送功能比更通用的读/写功能更有效。 通常差异可以忽略不计,但是当您超过 50k req/s 时,它开始增加。 Seastar 已经对传出数据使用 send,但它对传入请求使用 read,因此我做了相对简单的更改,将其切换为 recv。
|
|
吞吐量从 964k req/s 提高到 982k req/s,性能提高不到 2%。
火焰图分析
如果您查看火焰图左侧的读取/接收堆栈(read/recv),您会发现 __libc_recv 比 __libc_read 更直接。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-recv-syscall.svg?x=1198.2&y=757
{kind=link}
Remember to Flush
我通过在代码库中漫游并打开/关闭事物以查看它们做了什么来找到最终的优化。 使用 epoll 反应器后端时,output_stream 上的 batch_flushes 选项会在调用 flush() 时立即延迟调用 send()。 它旨在优化可能多次调用 flush() 的 RPC 工作负载,但它不会为我们的简单请求/响应工作负载提供任何好处。 事实上,它增加了一点开销,所以作为快速修复,我只是禁用了 batch_flushes。 https://github.com/talawahtech/seastar/commit/58545f05d0250d8dc720ddf422f22cb557ebc365
|
|
吞吐量从 982k req/s 增加到 1.0M req/s,性能提升 2.2%。
火焰图分析
https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-optimized.svg?x=1198.4&y=837 火焰图显示发送堆栈从 batch_flush_pollfn::poll 移动到 output_stream::flush
{kind=link}
我们的优化工作为我们的最终数字带来了心理上令人满意的基数 10, 达到了1.0M 请求/秒,仅使用良好的旧 Linux 内核。
最终获胜者是…
最终,DPDK 仍然保持着对内核 51% 的性能领先优势。 是多还是少取决于你的观点。 在我看来,当您比较内核/应用程序的未优化和优化版本时,我们已将 DPDK 的性能优势从 4.2 倍缩小到仅 1.5 倍。
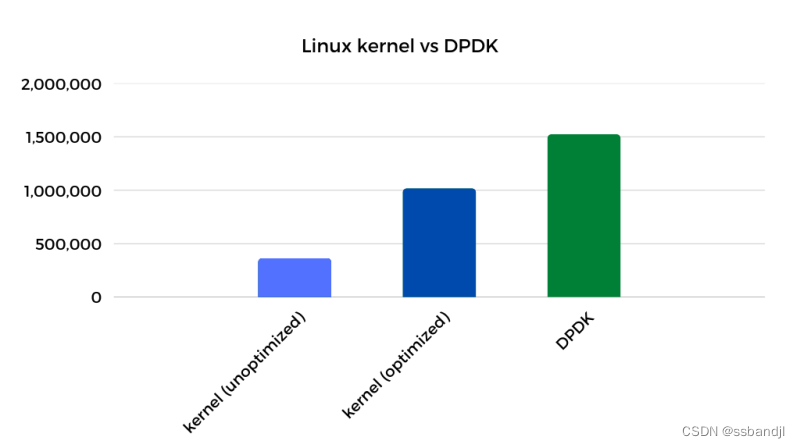
DPDK 注意事项
DPDK 的 51% 优势不容小觑,但是如果我让您陷入 DPDK 的空洞而不添加一些关于 DPDK 挑战的免责声明,那我就是失职了。
首先,它是一种小众技术,因此在线查找文章和示例(尤其是对于既定领域之外的用例)可能具有挑战性。
绕过内核意味着您也绕过了其久经考验的 TCP 堆栈。 如果您的应用程序使用基于 TCP 的协议(如 HTTP),您需要在用户空间中提供自己的 TCP 网络堆栈。 Seastar 和 F-Stack 等框架可以提供帮助,但将您的应用程序迁移到它们可能并非易事。
使用自定义框架也可能意味着您绑定到它支持的特定 DPDK 版本,这可能不是您的网络驱动程序或内核支持的版本。
在绕过内核时,您还绕过了用于保护、监控和配置网络流量的现有工具和功能的丰富生态系统。 您习惯使用的许多工具和技术不再有效。
如果您使用轮询模式处理,您的 CPU 使用率将始终为 100%。 除了不节能/不环保之外,它还难以使用 CPU 使用率作为衡量标准来快速评估/排除工作负载故障。
基于 DPDK 的应用程序可以完全控制网络接口,这意味着:
您必须有多个接口。 如果要修改设备设置,则必须在启动前或通过应用程序进行。 如果要捕获指标,则必须配置应用程序才能执行此操作; 即时进行故障排除要困难得多。 话虽这么说,除了纯粹的性能之外,可能还有其他理由去追求定制的 TCP/IP 堆栈。 应用程序内 TCP 堆栈允许应用程序精确控制内存分配(避免应用程序和内核之间的内存争用)和调度(避免 CPU 时间争用)。 这对于不仅力求最大吞吐量而且力求出色的 p99 延迟的应用程序来说可能很重要。
归根结底,这是关于平衡优先事项。 例如,尽管 ScyllaDB 团队偶尔会收到与内核网络堆栈相关的反应器停顿报告,但他们仍然选择坚持使用其旗舰产品的内核,因为切换到 DPDK 绝非易事。
Speculative Execution Mitigations 推测执行缓解措施
在这篇文章的开头,我掩盖了我在开始优化应用程序之前所做的操作系统级优化。 从高层次上看,这些变化与我之前的帖子类似,对于那些想要深入了解更多细节的人,我计划“在某个时候”写一篇内核 4.14 vs 5.15 的帖子。 然而,在这个内核与 DPDK 的对决中,有一项特殊的优化值得进一步分析:禁用推测执行缓解措施。
我不会重复我对这些缓解措施的看法,您可以在此处阅读(https://talawah.io/blog/extreme-http-performance-tuning-one-point-two-million/#_2-speculative-execution-mitigations)。 出于本文的目的,我将它们关闭,但如果您查看下图,您会发现重新打开它们会显示一些有趣的结果。
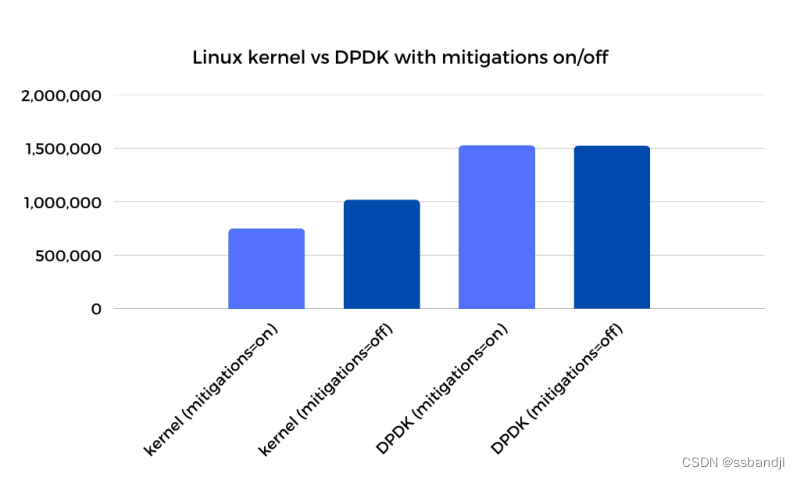 正如您所看到的,虽然禁用缓解措施会在内核端产生 33% 的性能提升,但它对 DPDK 性能的影响为零。 这导致两个主要结论:
正如您所看到的,虽然禁用缓解措施会在内核端产生 33% 的性能提升,但它对 DPDK 性能的影响为零。 这导致两个主要结论:
对于必须进行推测执行缓解的环境,DPDK 代表了比内核 TCP 堆栈更大的性能改进。
绕过 I/O 系统调用接口的 io_uring 等内核技术在提高大多数工作负载的性能方面具有更大的潜力。
大多数人不会禁用 Spectre 缓解措施,因此启用它们的解决方案很重要。 我不是 100% 确定所有的缓解开销都来自系统调用,但按理说,其中很多开销来自用户到内核和内核到用户转换中的安全强化。 这种影响在火焰图上的系统调用相关函数中肯定是可见的。 https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/tcp_httpd-final-optimized-mitigations-on.svg?x=1197.4&y=837
{kind=link}
结论
我们已经证明,即使将操作系统和应用程序优化到极致,DPDK 仍然比内核网络堆栈有 51% 的性能领先。 我没有将这种差异视为不可逾越的障碍,而是将差距视为内核方面未实现的潜力。 这个差距只是提出了一个问题:在不损害其通用性质的情况下,Linux 内核可以在多大程度上针对每核线程应用程序进一步优化?
DPDK 让我们了解在理想情况下什么是可能的,并作为努力实现的目标。 即使差距不能完全缩小,它也会量化任务并将障碍抛向更清晰的焦点。
一个非常明显的障碍是每秒进行数百万次系统调用时系统调用接口的开销。 值得庆幸的是,io_uring 似乎为该特定挑战提供了一个潜在的解决方案。 我一直在密切关注 io_uring,因为它仍在大量开发中。 我特别兴奋地看到最近一波以网络为中心的优化浪潮,例如繁忙的轮询支持、recv 提示,甚至是无锁 TCP 支持等实验性探索。 它在我要“很快”测试的事情清单上仍然排在前列。 https://twitter.com/axboe/status/1504263869824266241 https://twitter.com/axboe/status/1502002250557923337 https://twitter.com/axboe/status/1519404690001305600 https://twitter.com/axboe/status/1514013578629574656
附录
特别感谢 特别感谢我的审阅者:Dor 和 Kenia,以及 Seastar Slack 频道和邮件列表中的每个人,尤其是 Piotr、Avi 和 Max。
C/C++ 入门 我利用我有限的 C 知识,结合基本的模式识别,在 Seastar 的 C++ 代码库中摸索了比我应该拥有的时间更长的时间,但是当需要添加 get_cpu_to_shard_mapping() 函数时,我决定停止自欺欺人并学习一点 C++。 如果您发现自己处于类似的困境,我推荐 A Tour of C++ 作为一本不错的入门书。 如果您还需要快速复习 C,我推荐 Essential C 和 Pointers and Memory。 https://isocpp.org/tour http://cslibrary.stanford.edu/101/EssentialC.pdf http://cslibrary.stanford.edu/102/PointersAndMemory.pdf
参考
更多细节和链接请查看原文:
https://talawah.io/blog/linux-kernel-vs-dpdk-http-performance-showdown/#perfect-locality-and-busy-polling-take-two

晓兵
博客: https://logread.cn | https://blog.csdn.net/ssbandjl
weixin: ssbandjl
公众号: 云原生云
Author 晓兵
首发链接: https://blog.csdn.net/ssbandjl
博客: https://logread.cn | https://blog.csdn.net/ssbandjl
weixin: ssbandjl
公众号: 云原生云
![]()
- 原文作者:晓兵
- 原文链接:https://logread.cn/post/linux/linux_kernel_vs_dpdk/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。